ドキュメントのこの部分では、FogFlow の概念的な概要と、インスタンスの開発で FogFlow を使用する方法について説明します。 FogFlow は、動的な NGSI ベース (Next Generation Service Interface - based) のデータ処理フローをプロデューサーと コンシューマーの間でオンデマンドで調整し、タイムリーな結果を提供して迅速なアクションを実行するためのクラウドおよびエッジ 環境です。コンテキスト プロデューサーはセンサー ベースのデバイスですが、コンシューマーは何らかのアクションを実行する コマンドを受信するアクチュエータ デバイスです。
FogFlow は、分散型で自律的な方法で IoT サービス オーケストレーションの決定を実行できます。つまり、各 FogFlow エッジ ノードは、ローカル コンテキスト ビューに基づいてのみ独自の決定を行うことができます。このようにして、ワークロードの 大部分は、常に中央のクラウドに依存することなく、エッジで直接処理できます。この "cloudless" アプローチにより、FogFlow は高速な応答時間を提供するだけでなく、高いスケーラビリティと信頼性を実現します。
FogFlow ベースのインスタンスを定義してトリガーするには、このドキュメントのインテント ベースのプログラミング モデル (Intent based programming model) の部分を参照してください。
1. コア コンセプト¶
1.1. オペレーター (Operator)¶
FogFlow では、オペレーターは、リスニング ポートを介して NGSI10 ノーティファイ メッセージとして特定の入力ストリームを 受信し、受信したデータを処理し、特定の結果を生成し、生成された結果を NGSI10 アップデートとして公開するタイプの データ処理ユニットを提示します。
オペレーターの実装は、少なくとも1つの Docker イメージに関連付けられています。さまざまなハードウェアアーキテクチャ (64ビットまたは32ビットの x86 および ARM など) をサポートするために、同じオペレーターを複数の Docker イメージに 関連付けることができます。
1.2. タスク(Task)¶
タスクは、サービス トポロジー内の論理データ処理ユニットを表すデータ構造です。 各タスクはオペレーターに関連付けられています。タスクは、次のプロパティで定義されます。
- name: このタスクを表示するための一意の名前。
- operator: 関連するオペレーターの名前。
- groupBy: タスク インスタンスの単位を制御するための粒度。サービス オーケストレーターが作成する必要のあるタスク インスタンスの数を決定するために使用されます。
- input_streams: 選択された入力ストリームのリスト。各入力ストリームはエンティティ タイプによって識別されます。
- output_streams: 生成された出力ストリームのリスト。各ストリームはエンティティ タイプによって識別されます。
FogFlow では、各入力/出力ストリームは、NGSI コンテキスト エンティティのタイプとして表されます。 これらは通常、エンドポイント デバイスまたはデータ処理タスクのいずれかによって生成および更新されます。
実行時に、groupBy プロパティで定義された粒度に従って、同じタスクに対して複数のタスク インスタンスを作成できます。 どの入力ストリームがどのタスク インスタンスに送られるかを決定するために、タスクの入力ストリームを指定するために 次の2つのプロパティが導入されています。
Shuffling: タスクの各タイプの入力ストリームに関連付けられています。その値は、ブロードキャスト (broadcast) またはユニキャスト (unicast) のいずれかです。
- broadcast: 選択した入力ストリームは、このオペレーターのすべてのタスク インスタンスに繰り返し割り当てられる必要があります
- unicast: 選択した各入力ストリームは、特定のタスク インスタンスに1回だけ割り当てる必要があります。
Scoped: 入力ストリームを選択するために要件のジオスコープを適用する必要があるかどうかを決定します。その値は true または false のいずれかです。
1.3. タスク インスタンス (Task Instance)¶
実行時に、タスクは入力データと指定された出力タイプを使用して FogFlow によって構成され、構成されたタスクは Docker コンテナーで実行されるタスク インスタンスとして起動されます。現在、各タスク インスタンスは、クラウドまたはエッジ ノードのいずれかで専用の Docker コンテナーにデプロイされています。
1.4. サービス テンプレート (Service Template)¶
各 IoT サービスは、サービス テンプレートによって記述されます。サービス テンプレートは、リンクされたオペレーターのセットを備えたサービス トポロジー、または単一のオペレーターを備えたフォグ ファンクションです。たとえば、サービス トポロジーを使用してサービス テンプレートを指定すると、次の情報が含まれます。
- topology name: トポロジーの一意の名前。
- service description: このサービスの内容を説明するテキスト。
- priority: トポロジー内のすべてのタスクの優先度レベルを定義します。これは、リソースをタスクに割り当てる方法を決定するためにエッジ ノードによって使用されます。
- resource usage: このトポロジーのタスクがエッジ ノードのリソースを排他的に使用できるかどうかを定義します。つまり、他のトポロジーのタスクとリソースを共有しないことを意味します。
現在、FogFlow は、開発者が設計フレーズ中にサービス トポロジーまたはフォグ ファンクションを簡単に定義して注釈を付けることができるグラフィカル エディタを提供しています。
1.5. 動的データ フロー (Dynamic data flow )¶
要件を受け取ると、トポロジー マスターはデータ フロー実行グラフを作成し、それらをクラウドとエッジにデプロイします。主な手順は、2つの主要なステップを含む次の図に示されています。
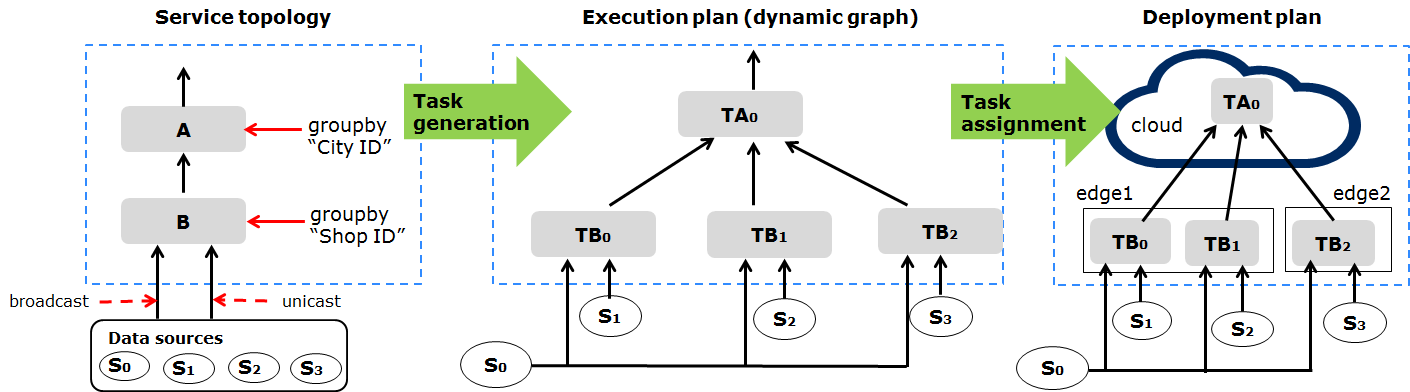
- service topology から execution plan に: トポロジー マスターのタスク生成アルゴリズムによって実行されます。
- 生成された実行プラン (execution plan) には次のものが含まれます: 1)サービス トポロジー (service topology) のどの部分がトリガーされるか。 2)トリガーされたタスクごとに作成する必要のあるインスタンスの数。 3)および各タスク インスタンスをその入力ストリームと出力ストリームでどのように構成するか。
- execution plan から deployment plan に: トポロジー マスターのタスク割り当てアルゴリズムによって実行されます。
- 生成された展開計画 (deployment plan) は、特定の最適化の目的に従って、どのタスク インスタンスをどのワーカー (クラウド内またはエッジ) に割り当てるかを決定します。現在、FogFlow のタスク割り当ては、エッジ ノードに過負荷をかけることなくノード間のデータ トラフィックを削減するように最適化されています。
2. FogFlow ストレージ (FogFlow Storage)¶
以前は、FogFlow はその内部データ構造を使用して、オペレーター、フォグ ファンクション、Docker イメージ、サービス トポロジーなどの FogFlow 内部エンティティを格納していました。FogFlow は、FogFlow 内部 NGSI エンティティを格納するための永続ストレージをサポートしていませんでした。したがって、FogFlow Broker がダウンするたびに、保存されているすべての内部エンティティが失われます。したがって、この問題を解決するために、FogFlow は Dgraph という名前の永続ストレージを使用しています。
永続ストレージは、そのデバイスへの電源が遮断された後もデータを保持するデータ ストレージ デバイスです。不揮発性ストレージと呼ばれることもあります。
Dgraph データモデルは、データセット、レコード、および属性で構成されています。ここで、レコードは Dgraph のデータの基本単位であり、属性はレコードスキーマの基本単位です。属性 (キーと値のペアとも呼ばれます) からの割り当ては、Dgraph のレコードを記述します。永続ストレージを使用したデータのフロー図は次のとおりです:
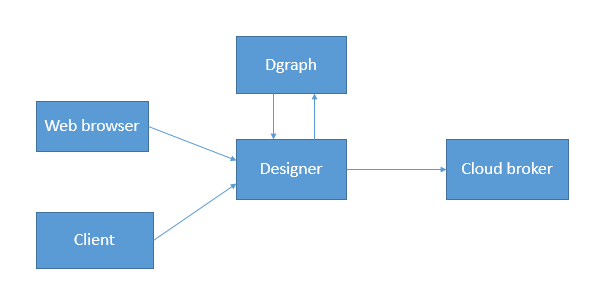
- FogFlow のユーザーは、デザイナーを介して Web ブラウザーを使用して FogFlow 内部エンティティーを作成できます。
- FogFlow のユーザーは、Designer を介してclient (curl) を使用して FogFlow 内部エンティティを作成できます。
- Designer は、必要に応じて、作成されたエンティティを Dgraph データベースに保存して取得できます。
- Designer は、Dgraph データベースから古い登録済みエンティティを取得し、Cloud Broker に登録できます。
グラフデータベースをサポートする利用可能なデータベースはたくさんあります。たとえば、Neo4j です。Dgraph はデータベースの使用率が最も高いデータベースの1つです。FogFlow は Dgraph を使用しています。Dgraph を選択した理由は次のとおりです:
- Dgraph は、グラフデータの読み込みに関して Neo4j より160倍高速です。
- Dgraph は、Neo4j と比較して5分の1のメモリを消費します。
- Dgraph は、ジョブ (job) を遂行するために必要なほとんどの機能をサポートしています。